1. Answer the correct option from the following: (10×1=10)
(i) Effort is measured using which one of the following units
(a) persons
(b) person-months
(c) months
(d) rupees
(ii) COCOMO estimation model can be used to estimate which one of the following:
(a) LOC
(b) Efforts
(c) Function points
(d) Defect density
(iii) What is the correct order in which a software project manager estimates various project parameters while using COCOMO
(a) Cost, effort, duration, size
(b) Cost, duration, effort, size
(c) Size, effort, duration ,cost
(d) Size, cost, effort, duration
(iv) A software requirements specification (SRS) document should avoid discussing which one of the following?
(a) Functional requirements
(b) Non-functional requirements
(c) Design specification
(d) Constraints on the implementation
(v) A DFD depicts which of the following?
(a) Flow of data
(b) Flow of control
(c) Flow of statements
(d) None of the above
(vi) Which of the following indicated is a kind of relationship?
(a) Aggregation
(b) Association
(c) Dependency
(d) Inheritance
(vii) DFD stands for
(a) Data Found Diagram
(b) Database Flow Diagram
(c) Data Fault Diagram
(d) None of the above
DFD stands for Data Flow Diagram
(viii) Which one of the following assertions is true?
(a) Code inspection is carried out on tested and debugged code
(b) Code inspection and code walkthrough are essentially synonymous
(c) Adherence to coding standards are checked during code inspection
(d) Code walkthrough makes code inspection redundant
(ix) Code review does not target to detect which of the following types of testing
(a) Algorithmic error
(b) Syntax error
(c) Programming error
(d) Logic error
(x) In the waterfall SDLC model, unit testing is carried out during which one of the following phases?
(a) Coding(b)
(b) Testing
(c) Design
(d) Maintenance
2. (a) What is software engineering? Explain its importance. (5)
Ans: Software engineering is systematic, disciplined, cost effective technique for software development. It is a branch of computer science, which uses well-defined engineering concepts required to produce efficient, durable, scalable, in-budget and on-time software products.
Software engineering is defined as a discipline whose aim is the production of quality software, software that is delivered on time within budget and that satisfies its requirements.
IEEE defines software engineering as – “Software engineering isthe application of a systematic, disciplined and quantifiable approach to the development, operation and maintenance of software”.
Importance of Software Engineering:
Software engineering is essential for creating reliable, efficient, and maintainable software systems. It plays a pivotal role in delivering software that meets user needs, complies with industry standards, and contributes to the success of organizations and businesses in today’s technology driven world.
Software engineering is important in today’s technology-driven world for several reasons:
Quality Assurance: Software engineering principles and practices ensure that software is developed with high quality and reliability. This is crucial to prevent software defects, security vulnerabilities that could lead to system failures or data breaches.
Efficiency: Proper software engineering techniques help in creating efficient and optimized software. This is vital for resource utilization, as efficient software consumes fewer system resources like memory and processing power.
Maintainability and Scalability: Software engineering allows for the design and development of scalable systems. Well-engineered software is easier to maintain and scale. This is essential for long-term success, as software needs to evolve over time to accommodate new features, technologies, and user requirements.
Cost Reduction: Properly engineered software can reduce costs in several ways. It can automate manual processes, reduce the need for physical infrastructure, and minimize errors and defects, which can be expensive to fix after deployment.
Maintenance and updates: Software engineering principles are essentials for maintaining and updating software over its life cycles. Good software engineering practices make it easier to maintain, update and extend software over time. This reduces the cost and effort required for ongoing software maintenance and enhancements.
User Experience: Software engineering is vital in creating user-friendly and intuitive software interfaces. A well-designed user interfaces enhances user satisfaction and adoption, and loyalty.
Innovation: Software engineering encourages innovation by facilitating rapid prototyping, experimentation, and the development of new features or products. It allows individuals and organizations to create new software products and services that can revolutionize industries and improve the quality of life. From smartphones to self-driving cars, innovation often begins with software engineering.
(b) What is software verification and software validation? Explain. (5)
Ans: In software testing, verification and validation are the processes to check whether a software system satisfies the specifications and that it fulfills its intended purpose or not.
Verification: Are we building the product right?
Validation: Are we building the right product?
Verification:
Verification is a process of determining if the software is designed and developed as per the specified requirements. It is the process of determining whether the output of one phase of software development conforms to that of its previous phase.
Verification is the process of evaluating a system or component to determine whether the products of a given development phase satisfy the conditions imposed at the start of that phase. It is the process of evaluating the intermediary work products of a software development lifecycle to check if we are in the right track of creating the final product.
Verification in software testing is a process of checking documents, design, code, and program in order to check if the software has been built according to the requirements or not.
Verification is the process to ensure that whether the product that is developed is right or not. The verification process involves activities like reviews, walkthroughs and inspection.
Validation:
Validation is the process of checking if the software (end product) has met the client’s true needs and expectations. It is the process of checking the validation of product. Validation helps to determine if the software team has built the right product. It is validation of actual and expected product. Validation is the dynamic testing.
Validation evaluates software to meet the user’s needs and requirements. It ensures the software fits its intended purpose and meets the user’s expectations.
Validation is conducted after the completion of the entire software development process. It checks if the client gets the product they are expecting. Validation focuses only on the output; it does not concern itself about the internal processes.
(c) Explain why spiral model is called meta model. (5)
Ans: The spiral model is often referred to as a “meta-model” because it serves as a framework or a high level concept that encompasses and combines various software development methodologies. It doesn’t prescribe specific steps or techniques but instead provides a flexible approach to software development.
The spiral model incorporates elements from other software development models like the waterfall Model, iterative Model and Incremental Model. It encourages iterative development, risk assessment and a focus on managing uncertainties in the project. This adaptability and integration of different methodologies make it a meta-model, as it guides the development process without being overly prescriptive.
In essence, the spiral model is a meta model because it doesn’t define a specific set of rules but rather offers a conceptual framework that can be customized to fit the unique needs and challenges of a particular project.
Here are some reasons why the Spiral Model is considered a meta-model:
Adaptability: The Spiral Model is designed to be highly adaptable to different project types and development environments. It doesn’t prescribe a fixed set of phases or activities; instead, it encourages tailoring the process to the specific needs and risks of the project.
Integration: It can incorporate elements from other software development methodologies, such as the Waterfall Model, Agile practices, or specific industry standards. This flexibility allows organizations to integrate their preferred practices and processes within the Spiral Model’s framework.
Iterative and Incremental: The Spiral Model inherently promotes an iterative and incremental approach to software development. It emphasizes the importance of multiple iterations, each of which may follow a different development process, depending on project requirements.
Risk Management: The Spiral Model places a significant emphasis on risk management. It acknowledges that software projects often involve uncertainties and risks, and it provides a structured way to identify, assess, and mitigate these risks throughout the development process.
Continuous Improvement: The model encourages continuous improvement by reflecting on past iterations and incorporating lessons learned into future ones. This ongoing assessment and adaptation make it a meta-model that can evolve over time.
Due to these characteristics, the Spiral Model serves as a meta-model that can encompass various approaches to software development. It provides a structured and iterative framework for managing complex projects while allowing organizations to tailor it to their specific requirements, making it a valuable choice for projects with evolving or uncertain needs.
3. (a) Briefly explain the skill necessary for managing software projects. (5)
Ans: Managing software projects is a complex task that requires a diverse set of skills to ensure successful planning, execution, and delivery. Here’s a brief overview of the skills necessary for effective software project management:
Project Planning: The ability to create detailed project plans, define project scope, set objectives, estimate resources, and develop schedules is essential for keeping the project on track.
Communication: Strong communication skills are vital for conveying project goals, requirements, and progress to stakeholders, team members, and clients. Effective listening is equally important for understanding feedback and concerns.
Leadership: Project managers need leadership skills to motivate and guide their teams, resolve conflicts, and provide direction. Leading by example can inspire team members to meet their goals.
Technical Knowledge: A fundamental understanding of software development processes, technologies, and tools is crucial for a software project manager to make informed decisions and communicate effectively with the development team.
Time Management: Efficiently allocating time to tasks, setting milestones, and ensuring the project stays on schedule. The capacity to prioritize tasks, allocate resources efficiently, and meet deadlines is crucial for managing project schedules and ensuring timely delivery.
Risk Management: Skill in identifying potential project risks, assessing their impact, and developing strategies to mitigate them is essential to avoid disruptions and unexpected challenges.
Budgeting and Cost Management: Managing project budgets, tracking expenses, and making informed financial decisions are essential for keeping the project financially viable.
Problem-Solving: Quickly identifying and resolving issues that arise during the project’s lifecycle. Project managers should be skillful at identifying issues, analyzing their root causes, and implementing effective solutions to keep the project on course.
Quality Assurance: Implementing quality control processes to ensure the delivered software meets the required standards and specifications. Ensuring the quality of the software being developed is part of a project manager’s responsibility. This involves defining quality standards, monitoring compliance, and addressing quality-related issues.
Continuous Improvement: The willingness to learn from past projects and continuously improve project management practices. Encouraging a culture of continuous improvement within the team and the project management processes is essential for achieving better results in future projects.
(b) Briefly explain the metrics for project size estimation in detail. (5)
Ans: Project size estimation matrices, also known as software sizing metrics, are used in software project management to estimate the size of a software project. These matrices help in planning, resource allocation, cost estimation and scheduling.
Project size estimation in software development is typically done using various matrices. Two commonly used matrices for project size estimation are Lines of Code (LOC) and Function Points (FP). While LOC provides a basic and easy-to-measure metric for project size estimation, FP offer a more comprehensive and accurate approach that takes into account the functionality and complexity of the software, making it a valuable tool for estimating various project parameters.
Here’s a brief explanation of each:
Lines of Code (LOC):
Definition: LOC is a simple and widely used metric that counts the number of lines of code in a software project.This includes lines of actual code, comments and blank lines.
Usage: LOC is used to estimate project size and can serve as a basis for estimating development effort, cost, and schedule.
Advantages:
- Easy to measure using automated tools.
- Provides a quick a straightforward estimate.
Limitations:
- Doesn’t for variations in code complexity or functionality.
- Different programming languages may have different LOC counts for the same functionality.
Function points (FP):
Definition: FP is more comprehensive metric that measures the functionality provided by a software application based on user inputs, outputs, inquiries and data elements.
Usage: FP is used to estimate project size and is considered more accurate than LOC because it accounts for the complexity and functionality of the software.
Advantages:
- Focuses on what the software does for users, considering its business functionality.
- Helps in estimating effort, cost and schedule more accurately.
Limitations:
- Requires detailed analysis and expertise to determine function point values.
- Subject to interpretation, which can lead to variations in estimates
Function points are typically calculated using a standardized process that involves identifying and accessing five components.
- External Inputs (EI): Count of unique inputs from external sources.
- External Outputs (EO): Count of unique outputs to external sources.
- External Inquiries (EQ): Count of unique queries or requests for information from external sources.
- Internal Logical Files (ILF): Count of unique data groups maintained by the system.
- External Interface Files (EIF): Count of unique files used by the system but maintained by external applications.
The Function Point Analysis process assigns complexity values to each of these components, and a weighted sum is used to calculate the function points. These function points can then be used to estimate various aspects of the project, such as development effort, cost and duration.
(c) Explain the difference between expert judgement and Delphi cost estimation technique. (5)
Ans: Expert judgment and the Delphi cost estimation technique are both methods used in project management and cost estimation, but they differ in their approach and implementation.
The main difference between expert judgment and the Delphi technique is in their approach to gathering and synthesizing expert opinions. Expert judgment is often quick and based on the input of individual experts or a small group, while the Delphi technique is a more structured, iterative, and collaborative approach involving multiple experts, often used for addressing complex and uncertain problems.
Here are the key differences between the two:
Expert Judgment:
Nature of Input:
- Subjective: Expert judgment relies on the opinions, insights, and expertise of one or more individuals who have experience in the relevant domain. It is a subjective approach based on expert knowledge.
Number of Participants:
- Individual or Small Group: Expert judgment often involves a single expert or a small group of experts who provide their assessments or estimates based on their individual experiences and insights.
Interactions:
- Limited Interaction: There may be limited interaction or collaboration among experts during the estimation process. Experts provide their opinions independently.
Use Cases:
- Wide Range: Expert judgment can be applied to various project management and estimation tasks, including risk assessment, cost estimation, schedule planning, and quality assurance.
Speed and Efficiency:
- Quick Decision-Making: Expert judgment can be a relatively quick method for obtaining estimates or judgments from experienced professionals.
Delphi Cost Estimation Technique:
Nature of Input:
- Iterative and Anonymous: The Delphi technique is an iterative, structured process that gathers opinions and estimates anonymously from a panel of experts. Experts provide their input without knowing the identity of other participants.
Number of Participants:
- Multiple Experts: Delphi typically involves multiple experts, often chosen for their diverse perspectives and expertise in the relevant domain.
Interactions:
- Iterative Interaction: Delphi involves a series of rounds or iterations. In each round, experts review the aggregated opinions and feedback from previous rounds, potentially leading to revised estimates and judgments.
Use Cases:
- Complex and Uncertain Problems: The Delphi technique is particularly useful for complex and uncertain problems, such as long-term cost estimation or forecasting, where consensus among experts is challenging to achieve.
Speed and Efficiency:
- Time-Consuming: Delphi can be a time-consuming process, especially when multiple rounds are required to converge toward a consensus. It is not as quick as soliciting a single expert’s opinion.
4. (a) Briefly explain all the characteristics of good SRS documents. (5)
Ans: Software requirements specification should be unambiguous, accurate, complete, efficient, and of high quality, so that it does not affect the entire project plan. An SRS is said to be of high quality when the developer and user easily understand the prepared document.
The characteristics of SRS are explained below:
Correctness: Every requirement in the SRS must be true requirements of the system. User review is used to ensure the correctness of requirements stated in the SRS. SRS is said to be correct if it covers all the requirements that are actually expected from the system. Correctness ensures that all specified requirements are performed correctly.
Completeness: SRS is complete when the requirements clearly define what the software is required to do. This includes all the requirements related to performance, design and functionality. SRS should contain all sorts of input and it should provide features for handling all functions of the system.
Consistency: Requirements in SRS are said to be consistent if there are no conflicts between any set of requirements. For example, there can be a case when different requirements can use different terms to refer to the same object. SRS should use consistent terminologies so that there is no requirement that conflicts with another.
Unambiguousness: SRS is unambiguous when every requirement specified in SRS document has only one interpretation. This implies that each requirement is uniquely interpreted. In case there is a term used with multiple meanings, the requirements document should specify the meanings in the SRS so that it is clear and simple to understand.
Verifiability: SRS is verifiable if and only if there exists some cost-effective process that can check whether the final product meets the requirement.
Modifiability: SRS Document must be modifiable. The requirements of the user can change, hence requirements document should be created in such a manner that those changes can be modified easily, consistently maintaining the structure and style of the SRS.
Traceability: SRS is traceable when the source of each requirement is clear and facilitates the reference of each requirement in future. For this, forward tracing and backward tracing are used. Forward tracing implies that each requirement should be traceable to design and code elements. Backward tracing implies defining each requirement explicitly referencing its source.
(b) What do you mean code review? Explain code walkthrough and code inspection. (2+3=5)
Ans: Code review, also known as a “peer review” or “peer inspection,” is a systematic examination of software source code. It involves one or more individuals (often fellow developers or team members) reviewing code written by another developer to assess its quality, correctness, maintainability, and adherence to coding standards and best practices.
The primary goals of code review are:
Improvement of Code Quality: Code review helps identify and rectify issues, bugs, and design flaws in the code before it is integrated into the project. This leads to higher-quality software with fewer defects.
Early Detection of Defects: By catching and addressing issues early in the development process, code review reduces the cost and effort required to fix defects later in the software development lifecycle.
Validation of Design Decisions: Code reviews can validate whether the code aligns with the intended design and architecture of the software.
Increased Confidence: The review process provides confidence to both the author and the team that the code is of high quality and meets the project’s requirements.
Code Walkthrough and Code Inspection:
“Code walkthrough” and “code inspection” are two distinct methods of reviewing and assessing software code to identify issues, improve quality, and ensure adherence to coding standards and best practices in software development.
Code Walkthrough:
A code walkthrough is a collaborative, informal review process where developers or team members gather to review code as a group. The primary purpose is to promote knowledge sharing, discuss code-related concerns, and identify potential issues in a less formal and more educational setting.
Here are the key features of code walkthroughs:
Collaborative Discussion: During a code walkthrough, the author of the code explains their implementation to other team members. Participants can ask questions, seek clarifications, and engage in discussions about the code’s design, logic, and functionality.
Learning Opportunity: Code walkthroughs are often used as a learning opportunity for team members, especially less experienced developers. It allows them to understand different coding techniques, design patterns, and best practices.
Informal Setting: Unlike formal code inspections, code walkthroughs are relatively informal and focused more on understanding and knowledge sharing than on finding defects. The goal is to catch issues early but not necessarily to conduct a thorough defect hunt.
Effective Communication: Code walkthroughs facilitate effective communication within the team and help ensure that everyone is on the same page regarding the code’s implementation.
Code Inspection:
Code inspection, also known as a “code review” or “formal inspection,” is a structured and systematic process for reviewing code. It is a formal quality assurance practice used to identify defects, ensure code quality, and enforce coding standards.
Here are the key features of code inspections:
Structured Process: Code inspections follow a well-defined and structured process. The code is reviewed systematically, with predefined roles and responsibilities for participants, and a specific checklist or set of criteria to evaluate.
Defect Detection: The primary objective of a code inspection is to detect defects, such as bugs, logic errors, coding standards violations, and potential improvements. It aims to identify and address issues comprehensively.
Formal Documentation: Code inspections typically involve documentation of defects and issues found during the review, as well as resolutions or action plans for addressing them.
Checklists and Standards: Code inspections often employ checklists or coding standards documents to guide the review process. These documents outline the expected coding practices and requirements.
Traceability: Code inspections may involve tracing requirements to code to ensure that code changes align with project requirements and specifications.
(c) Briefly explain all the characteristics of good software design. (5)
Ans: Following are the characteristics of a good software design:
- Correctness: A good softwaredesign should correctly implement all the functionalities identified in the SRS document.
- Completeness: Completeness requires thatall the different components of the design should be verified i.e., all the relevant data structures, modules, external interfaces and module interconnections are specified.
- Consistency: Consistency requires that there should not be any inconsistency in the design.
- Efficiency: The software design must be efficient. Efficiency of any system is mainly concerned with the proper use ofresources by the system. The need for efficiency arises due to cost considerations. If some resources are scarce and expensive, it is then desirable that those resources be used efficiently.
- Understandability: A good design should be easily understandable, unless a design is easily understandable, it would be difficult to implement and maintain it.
- Traceability: Traceability is an important property that can get design verification. It requires that all the design elements must be traceable to the requirements.
- Maintainability: The software design must be in such a way that modifications can be easily made in it. This is because every software needs time to time modifications and maintenance. Any change made in the software design must not affect the other available features, and if the features are getting affected, then they must be handled properly.
5. Write short notes of the following (any three): (3×5=15)
(a) DFD
(b) UML diagrams (any two)
(c) System testing
(d) Polymorphism
(a) DFD:
DFD (Data Flow Diagram) is an important tool used by system analysts. The flow of data of a system or a process is represented by DFD. A data flow diagram (DFD) is a visual representation of the flow of information through a process or a system.
It is a graphical representation of flow of data in an information system. It can be used to represent a system in terms of the input data to the system, various processing carried out on those data, and the output data generated by the system.
In nutshell, data flow diagrams simply provide a visual representation of how data is handled in a system. The main merit of DFD is that it can provide an overview of what data a system would process, what transformations of data are done, what files are used and where the results flow. The graphical representation of the systems makes it a good communication tool between a user and analyst. DFDs are structured in such a way that starting from a simple diagram which provides a broad overview at a glance, they can be expanded to hierarchy of diagrams giving more and more detail. The data flow diagram provides information about the process itself, outputs and inputs of each entity, and the various sub processes the data moves through.
Components of Data Flow Diagrams:
The data flow diagram shows data inputs, outputs, storage, and flow of data using symbols and shapes like rectangles, circles, and arrows. DFD mainly consists of four components. The components of DFD are —-
- External Entities
- Processes
- Data Store
- Data Flow
| Name | Description | Symbol |
| External Entity | It is represented by a rectangle and simply depicts a source or destination of data. | |
| Process | It is represented by a circle and depicts how the data is handled and processed in the system. | |
| Data Store | It is represented by open-ended rectangles and depicts a location where data is stored in the system. A repository of data. | |
| Data Flow | It is represented by an arrow and depicts the flow of data between the entities, processes and data stores. |
(b) UML diagrams:
UML stands for Unified Modeling Language. It is a language for creating models. UML is a rich language to model software solutions, application structures, system behavior and business processes. UML is a modern approach to modeling and documenting software. In fact, it’s one of the most popular business process modeling techniques.
A UML diagram is a diagram based on the UML with the purpose of visually representing a system along with its main actors, roles, actions, artifacts or classes, in order to better understand, alter, maintain, or document information about the system.
UML is not a programming language, it is rather a visual language. It is a way of visualizing a software program using a collection of diagrams. UML helps software engineers, businessmen and system architects with modelling, design and analysis. Mainly, UML has been used as a general-purpose modeling language in the field of software engineering.
Types of UML diagrams:
There are several types of UML diagrams and each one of them serves a different purpose. Diagrams in UML can be broadly classified as: Structural UML diagram and Behavioral UML diagram.
Structural Diagrams:
Structural UML diagrams, as the name would suggest, shows how the system is structured. It depicts the structure of a system or process. Structure diagrams show the things in the modeled system. In a more technical term, they show different objects in a system.
The structural diagrams represent the static aspect of the system. These static aspects represent those parts of a diagram, which forms the main structure and are therefore stable.
Structural Diagrams include: Component Diagrams, Object Diagrams, Class Diagrams and Deployment Diagrams.
Behavioral Diagrams:
Behavioral diagrams describe the behavior of the system, its actors, and its building components. They describe how the objects interact with each other to create a functioning system.
Behavior diagrams show the dynamic behavior of the objects in a system, which can be described as a series of changes to the system over time
Behavior diagrams include: Use Case Diagrams, State Diagrams, Activity Diagrams and Interaction Diagrams.
Structural Diagrams:
Class Diagram: The most widely used UML diagram is the class diagram. It is the main building block of any object-oriented solution. Class diagrams are the backbone of almost every object-oriented method. It describes the static structure of a system.
It shows the classes in a system, attributes, and operations of each class and the relationship between each class. Class UML diagram is the most common diagram type for software documentation. It is a central modeling technique that runs through nearly all object-oriented methods.
Behavior Diagrams:
Use Case Diagrams: Use case diagrams model the functionality of a system using actors and use cases. They are widely used to illustrate the functional requirements of the system and its interaction with external agents (actors). Use case diagrams give a graphic overview of the actors involved in a system, different functions needed by those actors and how these different functions interact.
Activity Diagrams: In software development, activity diagram is generally used to describe the flow of different activities and actions. Activity diagrams illustrate the dynamic nature of a system by modeling the flow of control from activity to activity.
Activity diagrams represent workflows in a graphical way. They can be used to describe the business workflow or the operational workflow of any component in a system. The activity diagram focuses on representing various activities. Activity diagrams are normally employed in business process modeling.
Sequence Diagram: A sequence diagram is an interaction diagram. Sequence diagram simply depicts interaction between objects in a sequential order i.e. the order in which these interactions take place.
A sequence diagram, sometimes referred to as an event diagram or an event scenario, shows the order in which objects interact. Sequence diagrams describe how and in what order the objects in a system function. These diagrams are widely used by businessmen and software developers to document and understand requirements for new and existing systems.
(c) System testing:
It is performed after integration testing and before acceptance testing and aims to verify that the integrated components of the system function correctly together and meet the specified requirements.
Whenever we are done with the unit and integration testing, we can proceed with the system testing. Here the entire software is tested. The reference document for this process is the requirements document. The goal is to see if the software meets its requirements.
The purpose of system testing is to validate an application’s accuracy and completeness in performing the functions as designed.
System testing is a critical phase in software testing as it validates that the entire software system, including its various components and interfaces, is working correctly and meeting the defined requirements and quality standards. Successful system testing is a key milestone before the software is released for user acceptance testing and eventual deployment.
Various Types of System Testing:
Regression Testing
A regression test is carried as part of system testing to check and detect if there is a problem in the system as a result of a change made to another component of the system. It ensures that any modifications made throughout the development process did not introduce a new flaw, and that previous defects will not reappear as new software is added over time.
Load Testing:
Load testing is done as part of system testing to see if the system can sustain real-time loads. This testing is needed to know that a software solution will work under a real load.
Functional Testing
A system’s functional testing is done to see if there are any missing functions in the system. The tester creates a list of critical functions that should be included in the system and that can be added during functional testing to improve the system’s quality.
Recovery Testing
This test is carried out to show software solutions that are reliable, trustworthy, and can successfully cover the possibility of a crash.
Alpha testing (α-testing):
It is performed by development team responsible to test the system, mostly testing team. It is responsibility of the development team to make sure that point to point functionality as mentioned in SRS document is working properly and anything isn’t missed. If anything is breaking then it must be fixed and properly tested.
Beta testing (ß-testing):
It is performed by a friendly set of customers to make sure that everything is all fine before finally submitting product for client evaluation.
(d) Polymorphism:
This is the ability to define different functions or classes as having the same name, but taking different data type. OOD languages provide a mechanism where methods performing similar tasks but vary in arguments, can be assigned same name. This is called polymorphism, which allows a single interface performing tasks for different types. Depending upon how the function is invoked, respective portion of the code gets executed.
6. (a) What is black box testing? Explain equivalence class partitioning and boundary value analysis. (2+3=5)
Ans: Black box testing is a technique of software testing which examines the functionality of software without knowing into its internal structure or coding. It is the method that does not consider the internal structure, design, and product implementation to be tested. In Black-box testing, a tester doesn’t have any information about the internal working of the software system. The Black Box only evaluates the external behavior of the system. The inputs received by the system and the outputs or responses it produces are tested.
Black box testing involves testing against a system where the code and paths are invisible. It is a process of checking the functionality of an application as per the customer requirement. The source code is not visible in this testing; that’s why it is known as black-box testing. Black-Box testing treats the software as a “Black Box” – with no information of inner working and it only checks the essential aspects of the system. While performing black box testing, a tester must know the system design and will not have access to the source code.

Equivalence Class Partitioning (ECP):
In this technique, input values to the system or application are divided into different classes or groups based on its similarity in the outcome.
Hence, instead of using each and every input value, we can now use any one value from the group/class to test the outcome. This way, we can maintain test coverage while we can reduce the amount of rework and most importantly the time spent.
Boundary Value Analysis:
Boundary value testing is focused on the values at boundaries.. The two ends, the inner and the outer limits are considered in this type of testing. We set a boundary value lower or higher than the actual limit to check the behavior of our system in both conditions.
Boundary value analysis tests the software with test cases with extreme values of test data. It is used to identify the flaws or errors that arise due to the limits of input data. This technique determines whether a certain range of values are acceptable by the system or not.
(b) What is debugging? Explain any two debugging approaches. (1+4=5)
Ans: Debugging is the process of finding bugs i.e. error in software or application and fixings them. It is a systematic process of spotting and fixing the number of bugs, or defects, in a piece of software so that the software is behaving as expected.
Debugging is the process of identifying and correcting errors or defects in software to ensure that it functions correctly. Software engineers use various approaches and techniques to debug their code effectively.
Here are two common debugging approaches in software engineering:
Manual Debugging: Manual debugging is a hands-on approach to finding and fixing bugs in software code. It involves human intervention to identify, isolate, and resolve issues. Manual debugging is valuable for understanding the code’s behavior in detail, especially for complex issues that may not be easily detected using automated tools alone.
Some common techniques used in manual debugging include:
- Print Statements: Developers insert print statements (also known as “debugging statements”) into their code to output specific variable values or messages at various points in the code. This helps them track the flow of the program and understand the state of variables. By analyzing these outputs, developers can pinpoint where the code is going wrong.
- Interactive Debuggers: Integrated Development Environments (IDEs) often come with debugging tools that allow developers to set breakpoints, step through code execution, inspect variables, and watch the program’s behavior in real-time. This interactive approach makes it easier to understand how the program behaves and where issues may occur.
- Code Review: Peer code review is an essential aspect of manual debugging. Another developer reviews the code to identify issues, logic errors, or potential bugs that the original programmer may have missed.
Automated Debugging: Automated debugging relies on tools and software to assist in identifying and diagnosing issues in code.
Some common automated debugging techniques include:
- Static Analysis Tools: These tools analyze the source code without executing it. They check for coding standards violations, potential logical errors, and common programming mistakes. For example, linters for JavaScript can identify syntax errors and coding style violations. Static analysis tools can catch issues before the code is even run, which helps improve code quality and maintainability.
- Dynamic Analysis Tools: Dynamic analysis tools work by monitoring the code as it runs. They can identify runtime errors, memory leaks, and performance bottlenecks. Profilers, for instance, measure the execution time of different parts of the code and highlight performance bottlenecks. Memory analyzers can identify memory leaks by tracking memory allocations and deallocations.
- Testing and Test Automation: Writing and running automated tests, including unit tests, integration tests, and end-to-end tests, is a crucial part of automated debugging. Test automation frameworks like JUnit for Java or PyTest for Python allow developers to create and execute tests automatically. These tests can catch regressions and ensure that code changes do not introduce new bugs.
(c) What is COCOMO? Explain organic and semidetached class of project development. (2+3=5)
Ans: COCOMO (COnstructive COst estimation MOdel) is a software cost estimation model proposed by Barry Boehm in 1981. It is one of the most popularly used software cost estimation models i.e. it estimates or predicts the effort required for the project, total project cost and scheduled time for the project
According to the Boehm any software development project can be classified into one of the following three categories based on the development complexity:
- Organic
- Semi-detached
- Embedded
1. Organic:
A development project can be considered of organic type, if the project deals with developing a well understood application program, the size of the development team is small, and the team members are experienced in developing similar types of projects.
2. Semidetached:
A development project can be considered of semidetached type, if the development team consists of a mixture of experienced and inexperienced staff. Team members may have limited experience on related systems but may be unfamiliar with some aspects of the system being developed.
7. (a) What is DFD? Draw a labeled DFD for college management system. Clearly show the context diagram and its hierarchical decompositions up to level 1. (Context diagram is the Level 0 DFD). 8
Ans: DFD (Data Flow Diagram) is an important tool used by system analysts. The flow of data of a system or a process is represented by DFD. A data flow diagram (DFD) is a visual representation of the flow of information through a process or a system.
It is a graphical representation of flow of data in an information system. It can be used to represent a system in terms of the input data to the system, various processing carried out on those data, and the output data generated by the system.
(b) Briefly explain all the phases of classical waterfall model with necessary diagram. 7
Ans: The classical waterfall model divides the life cycle into a set of phases. In this model, one phase can be started after the completion of the previous phase. That is the output of one phase will be the input to the next phase.
The different sequential phases of the classical waterfall model are shown in the diagram below:
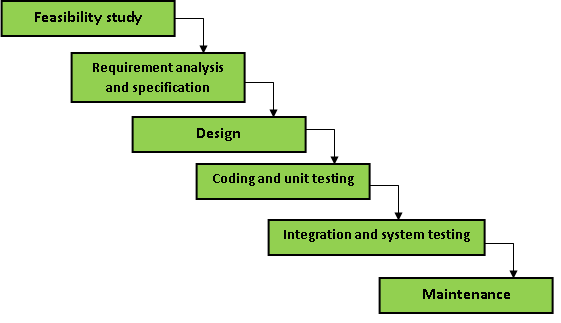
Feasibility Study: The main aim of this phase is to determine whether it would be financially and technically feasible to develop the software.
The feasibility study involves understanding the problem and then determining the various possible strategies to solve the problem. These different identified solutions are analyzed based on their benefits and drawbacks.
Project managers or teams, leaders examine each of the solutions in terms of what kind of resources required, what would be the cost of development and what would be the development time for each solution. Based on this analysis they pick the best solution and determine whether the solution is feasible financially and technically. They check whether the customer budget would meet the cost of the product and whether they have sufficient technical expertise in the area of development.
Requirements analysis and specification: The aim of the requirement analysis and specification phase is to understand the exact requirements of the customer and document them properly. This phase consists of two different activities.
Requirement gathering and analysis: The aim of ‘requirements gathering’ is to collect all relevant information from the customer regarding the product to be developed and then the gathered requirements are analyzed.
The goal of the requirements analysis part is to remove incompleteness and inconsistencies in these requirements. Once all ambiguities, inconsistencies, and incompleteness have been resolved and all the requirements have been properly understood, the requirements specification activity can start.
Requirement specification: The customer requirements identified during the requirements gathering and analysis activity are organized into a software requirement specification (SRS) document. SRS document serves as a contract between the development team and customers. Any future dispute between the customers and the developers can be settled by examining the SRS document.
Design: The goal of this phase is to convert the requirements specified in the SRS document into a structure that is suitable for implementation in some programming language. There are two design approaches being used at present: traditional design approach and object-oriented design approach.
Coding and Unit testing: In the coding phase software design is translated into source code. This phase is also called the implementation phase since the design is implemented into a workable solution in this phase. Each component of design is implemented as a program module.
The end-product of this phase is a set of program modules that been individually tested. After coding is complete, each module is unit-tested to determine the correct working of all individual modules. The aim of the unit testing phase is to check whether each module is working properly or not.
Integration and System testing Once the modules have been coded and unit tested, the Integration of different modules is undertaken. Integration of various modules is carried out incrementally over a number of steps. During each integration step, previously planned modules are added to the partially integrated system and the resultant system is tested. Finally, after all the modules have been successfully integrated and tested, the full working system is obtained and system testing is carried out on this.
System testing consists of three different kinds of testing activities as described below:
Alpha testing: Alpha testing is the system testing performed by the development team.
Beta testing: Beta testing is the system testing performed by a friendly set of customers.
Acceptance testing: After the software has been delivered, the customer performed acceptance testing to determine whether to accept the delivered software or reject it.
Maintenance: Maintenance is the most important phase of a software life cycle. The effort spent on maintenance is 60% of the total effort spent to develop full software. Maintenance can be referred as a process of enhancement in the software product according to the changing requirements of the user.
There are three types of maintenance:
Corrective Maintenance: This type of maintenance is carried out to correct errors that were not discovered during the product development phase.
Perfective Maintenance: This type of maintenance is carried out to enhance the functionalities of the system based on the customer’s request.
Adaptive Maintenance: Adaptive maintenance is usually required for modifying the system to cope with changes in the software environment.